OS2026上机真题

Lab 0 Exam
准备工作:创建并切换到lab0-exam-off分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab0-exam-off
初始化的 lab0-exam-off 分支在 msrc 目录下放置了完成本题所需的代码。
题目背景
在管理一个大规模程序项目的代码时,我们常会遇到这样的情况:代码存在多种构建规则,各规则之间存在共同依赖,而共同部分以外的依赖各自不同。在每次构建代码时,我们希望尽可能复用已有的编译结果,即仅对依赖项发生改变的部分重新进行编译,而不重新编译依赖项未发生改变的部分,以减少不必要的编译开销。
现在给定一些已经编写好的代码,需要你为其编写 Makefile ,进行如上所述情况的代码构建管理。
此外,编写的 Makefile 还需实现常用规则 clean 与 run ,分别用于:
- 清理生成的可执行程序、临时文件;
- 按照要求,依次运行编译好的程序。
文件说明
自动初始化完成后,题目有关代码将被放置在 msrc 目录下。msrc 的目录结构如下所示:
1 | * |
- 我们需要使用
calc1.c与calc2.c对同一组函数的不同定义,利用共同的依赖文件post_calc.c,common.h和主函数定义main.c编译出两个版本的程序ver1与ver2。 casegen.c是输入生成程序的源码,由其编译得到输入生成程序casegen。makefile.inc包含了两个变量定义INPUT_FILE与CASE_NUM,分别用于指定生成的输入文件名称,以及输入文件中包含的输入数据数。Makefile需要你根据题目要求进行编写。
题目要求
为了保证评测的正常进行,请不要在 msrc 目录下添加其他文件。
对于涉及编译程序的构建规则,请保证在其执行后,在文件目录下新增的文件,仅有可执行的程序。
假如你的编译过程中有中间产物 (如 .o 文件),你需要保证这些临时文件在可执行程序生成后被移除,否则会影响评测的正常进行。
要求你补全题目提供的 Makefile,使得其具备的构建规则满足以下要求:
casegen:编译生成输入生成程序casegen;ver1: 使用共同依赖,以及依赖calc1.c, 编译生成程序ver1;ver2: 使用共同依赖,以及依赖calc2.c, 编译生成程序ver2;all: 编译生成上述所有程序casegen,ver1,ver2;run: 先执行casegen获取输入, 再分别执行ver1,ver2获取输出;clean: 清理编译好的可执行文件casegen,ver1,ver2,以及运行过程中产生的所有后缀为.txt的临时文件。
此外,你需要保证 run 为 Makefile 的默认规则,即执行命令 make 与执行 make run 效果等价。
需要注意的是,run 和 clean 规则为伪规则,即不对应一个要实际生成的文件。在编写 Makefile 时,你需要确保 Makefile 对这两个规则的实现符合伪规则的预期行为。举例而言,当前目录下如果创建了一个名为 clean 的文件,则其不应影响 make clean 的正常执行。
作为额外要求,我们希望 Makefile 中规则的依赖项被规范填写,即对每条规则定义 <rule>: <dependency>,其中的 <dependency> 部分均包含当前规则的所有依赖项。
程序 casegen, ver1, ver2 的使用方法如下。有关输入参数可通过 makefile.inc 中的定义得到,并在 Makefile 中引用:
casegen <case_num> <input_file> ver1 <input_file> ver2 <input_file>
样例输出
此处仅介绍各程序的运行行为。各 Makefile 规则的预期行为详见题目要求。
- 程序
casegen将根据输入参数,在名为 的输入文件中,生成 组输入数据。 - 程序
ver1将从中读入输入数据,在文件 ver1_temp{i}.txt中写入第 ii 组输入的输出数据,并在标准输出中显示一段文本。 ver2的行为与ver1基本相同,唯输出文件的名称变为ver2_temp{i}.txt。
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
1 | $ cd ~/学号/ |
具体要求和分数分布如下:
| 测试点序号 | 评测内容 | 分值 |
|---|---|---|
| 1 | 测试 make ver1, make ver2 及编译所得程序的正确性 |
20 分 |
| 2 | 测试 make all |
20 分 |
| 3 | 测试 make run |
20 分 |
| 4 | 测试只执行 make 的行为 |
10 分 |
| 5 | 测试 make clean |
10 分 |
| 6 | 测试 clean, run 是否被正确设为伪规则 |
10 分 |
| 7 | 测试 Makefile 的依赖项是否被规范填写 | 10 分 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5case:6case:7
测试样例补充说明:
- 对于测试点7,若你的程序未能正确构建 Makefile 中的依赖关系,则报错信息会显示 “运行时遇到错误 exit-code=1”,正确则会生成正常的评测信息:“ACCEPTED: Dependency is set correctly!!”。
- 我们通过将你编写的 Makefile 放入测试样例提供的
msrc目录下进行测试。因此,你对msrc目录下其他文件的更改均不会生效。 makefile.inc中变量的定义,可能会因测试样例不同而产生变化。- 保证
makefile.inc中定义的样例数大于1个,小于100个。 - 保证提供的测试样例中,所有输入、输出文件均以
.txt作为文件后缀。 - 测试样例保证提供的程序可以正常编译,并表现出题目预期的行为。
提示:
- Makefile 中的伪规则,通过建立
.PHONY规则,并在其依赖列表中,加入需要设为伪规则的规则来实现。 - Makefile 中定义的规则,可以作为另一规则的依赖项。
- 如果你对 Makefile 的编写仍有疑惑,欢迎随时参阅指导书中 Makefile 有关的内容。
rm <file_name>指令可以用于移除文件<file_name>。<file_name>支持使用通配符,例如rm *.out代表删除当前目录下所有后缀为.out的文件。rm指令在删除不存在文件时会产生报错,这一报错可以通过加入-f参数抑制,例如rm -f *.out。
lab0 extra
准备工作
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab0-extra-off
题目背景
日志是排查问题的重要依据,系统管理员需要定期分析 Web 服务器的日志。
文件说明
服务器每天会产生两类日志:
访问日志(
access.log):记录 HTTP 访问请求,每行格式如下:1
IP地址 - - [时间 时区] 请求方法 请求路径 协议 状态码 响应大小
例如:
1
172.16.0.3 - - [2025-05-21:00:14:41 +0800] DELETE /images/logo.png HTTP/2.0 404 768
错误日志(
error.log):记录服务器错误信息,每行格式如下:1
日期 时间 [级别]: 消息
例如:
1
2025-07-06 02:02:05 [INFO]: Client disconnected
格式说明中的不同字段之间以空格分隔,除 消息 字段外,字段内部均不含空格。
服务器的日志根目录为 logs ,日志被保存在以对应日期命名的子目录中,结构如下:
1 | logs/ |
保证日志根目录不为空,且每个子目录中均存在两类日志文件,但不保证日志内容不为空。
题目要求
脚本:analyze.sh
用法:bash analyze.sh 日期
功能:分析指定日期的日志,日期格式为 YYYY-MM-DD
如果
日期未给出,则打印analyze.sh: No date provided到标准输出,并立即退出。如果
日期给出,则按如下要求分析对应日期(保证存在)的日志。新建报告根目录
reports,与日志根目录同级,报告均保存在以对应日期命名的子目录中。新建所有目录的权限为
rwxrwxr-x,所有普通文件的权限为rw-rw-r--。在指定日期的错误日志中检查是否存在含有
ERROR字样的记录,如果有则将这类记录筛选出来,按原顺序保存到相应报告子目录下的
error.log,否则不要创建此文件。在指定日期的访问日志中将
/127.0.0.1字样全部替换为/localhost,其它内容保持不变,全文保存到相应报告子目录下的
access.log,不要更改原文件。在指定日期的访问日志中统计每个
IP地址的总请求次数,并将结果按访问次数从高到低排序,保存到相应报告子目录下的
summary.txt,访问次数相同时的排序不做要求,每行格式如下:
1 | IP地址 总访问次数 |
提交时,只应提交脚本文件本身,不应提交你测试时产生的临时文件。
运行后,脚本不应执行多余操作,标准输出、标准错误和提交目录中不能有多余内容,可能的一种目录结构如下:
1 | logs/ |
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
$ cd ~/学号/ $ git add analyze.sh $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
测试点和分数说明如下:
共 10 个测试点,每个测试点 10 分。测试用例与给出的样例不同,每个测试点的主要评测内容如下所示。
| 测试点序号 | 评测内容 |
|---|---|
| 1, 2 | 错误处理 |
| 3 | 权限设置 |
| 4, 5 | 查找筛选 |
| 6, 7 | 全局替换 |
| 8, 9, 10 | 排序计数 |
提示
脚本参数用法详见指导书第 34 页
流程控制语句用法详见指导书第 35 页
权限设定命令用法详见指导书第 31 页
sed会将模式字符串当作正则表达式解析,如果需要将特殊符号按原字符解析则应使用反斜杠\转义。替换命令
s允许使用其它字符作为分隔符,分隔符如果出现在模式或替换字符串中也应该使用反斜杠\转义。例如:
's/\/\./\\./g'和's|/\.|\\.|g'等价,都可以将所有/.替换为\.sort: 连接所有文件,然后排序,并将结果写到标准输出用法:
sort [选项]... [文件]...选项:
-r逆序输出排序结果、-n按数值大小而非字典序进行排序uniq: 从输入文件或标准输入中过滤内容相同的相邻的行,并写到输出文件或标准输出用法:
uniq [选项]... [输入文件 [输出文件]]选项:
-c在每行之前加上该行的重复次数作为前缀
参考代码框架如下(实现方法不止一种):
1 |
|
# Lab 1 Exam
准备工作:创建并切换到 lab1-exam 分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab1-exam $ cd tools/readelf64
请在 tools/readelf64 目录下完成本题的代码实现。
题目背景
符号表(.symtab 节)是 ELF 文件中的一个重要节,记录了程序中的符号信息(如函数名、变量名等等),在链接和调试等过程中都有很重要的作用。因此,本题要求你实现一个简化版的 readelf64,输出 ELF 文件中所有节头的相关信息,并找出符号表(.symtab 节)对应节头在节头表中的下标。
课下练习中,我们已经实现过一个简化版 readelf,用于解析 32-bit little-endian ELF 文件 并输出节头地址。本题在此基础上进一步扩展。出于实用性考虑,要求同学们解析 64-bit little-endian ELF 文件。
需要注意的是,64 位 ELF 的整体解析思路与 32 位版本基本一致,主要差别在于所使用的数据结构和部分字段类型不同。更具体地说,本题中最直接的变化是:原先使用的 Elf32_ 系列结构体/变量,需要相应替换为 Elf64_ 系列结构体/变量。其余区别同学们在本题中无需考虑。
在 ELF 文件中,节头表中的每一个表项都描述了一个节(section)的信息,包括该节在文件中的偏移、大小、类型等。每个节头表表项都对应一个 Elf64_Shdr 结构体。通过解析节头表,我们可以获得 ELF 文件中所有节的基本信息。
本题要求你实现一个简化版的 readelf64,输出:
- 该 ELF 文件中的 总节数(即节头表表项数量);
- 符号表(
.symtab节)对应节头 在节头表中的下标; - 每一节的 名称(后文讲解获取方法)、文件偏移(
sh_offset)和大小(sh_size)。
相关知识说明
A. ELF64 文件头(Elf64_Ehdr *ehdr,与 32 位版本相对应)
ELF 文件开头为 ELF 文件头(ELF Header),它描述了这个 ELF 文件的整体布局信息。
它的作用是:告诉我们后续该去哪里找 节头表、节名称字符串表 等关键信息。
在本题中,你只需要 重点关注该结构体的以下字段:
e_shoff:节头表在 文件中的偏移;e_shnum:节头表表项的数量;e_shstrndx:节名称字符串表 的索引(即,其对应节头在节头表中的下标, 相关知识说明 C 中会展开讲解)
对应到实现中,可以通过 e_shoff 和 e_shnum 拿到与遍历节头表,用 e_shstrndx 定位 节名称字符串表。
B. 节头表与节头结构体(Elf64_Shdr *sh_table,与 32 位版本相对应)
节头表(Section Header Table,代码中对应 sh_table),可以理解为 “全体节的目录”。
在本题中,可以直接将节头表视为由 Elf64_Shdr 构成的数组,其作用是:按顺序记录 ELF 文件中每一个节(section)的关键信息,便于程序遍历和查询。
节头表里的每一个表项都对应一个 Elf64_Shdr 结构体(也称为节头)。若将节头表 sh_table 视为数组,则节头包括:sh_table[0], sh_table[1], … … , sh_table[e_shnum-1]。也就是说,每个 Elf64_Shdr 结构体描述一个节的信息。
它们的作用是告诉我们每个节的名字、内容在文件中的位置、大小等信息。
本题 重点关注该结构体的以下字段:
sh_name:节名称在 节名称字符串表内容字符串 中的 偏移;sh_offset:该节在 文件中的偏移;sh_size:该节的大小。
注意:sh_name 不是字符串指针,而是一个 偏移量。要想获得节名,需要先找到 节名称字符串表内容字符串。
对应到实现时,你需要遍历所有 Elf64_Shdr,利用 sh_name 解析节名,而后输出节名及该节的 sh_offset 和 sh_size。
C. 节名称字符串表
节名称字符串表(通常为 .shstrtab 节),本身也是 ELF 文件中的一个节。
它的内容本质上是一个由 \0 分隔的字符串池,存放所有节名。
例如,其内容字符串可能类似(不含双引号 "):
"\0.text\0.data\0.bss\0.symtab\0.strtab\0.shstrtab\0..."
它的作用是:配合每个节头里的 sh_name 偏移,解析出真实节名。
以上述节名称字符串表为例,若某个节头的 sh_name 为 1,则该节的名称为 .text;若 sh_name 为 13,则该节的名称为 .bss。
那么如何找到节名称字符串表,又如何借此获取某一节的节名称呢?
注意,ELF 文件头中的 e_shstrndx 表示 节名称字符串表 对应 节头 在 节头表 中的下标。
由此,给出获取某一节 节名称 的过程:
- 根据
e_shoff找到节头表(Elf64_Shdr *sh_table = ((char *)binary + ehdr->e_shoff)); - 取出下标为
e_shstrndx的那个节头(Elf64_Shdr *shstrShdr = &sh_table[ehdr->e_shstrndx]); - 通过该节头的
sh_offset(内容在文件中的偏移),找到 节名称字符串表 的 内容字符串 的位置,存到char *shstrtab(请大家参考 1. 中e_shoff的用法,完成相关代码); - 对于某一节(若其对应节头为
shdr),其节名可由char *sectionName = shstrtab + shdr->sh_name得到。
题目要求
本题要求你阅读 tools/readelf64 目录下文件,并补全代码。
重点查看以下文件:
elf64_mini.h:给出了本题涉及的若干 ELF64 相关结构体/变量的定义供参考;readelf64.c:本题需要补全的核心代码。
你需要在 tools/readelf64/readelf64.c 中补全代码,完成以下功能:
- 读取 ELF64 文件头;
- 定位 节头表;
- 通过 节名称字符串表 解析 节头的名称;
- 遍历所有节头,输出每一节的:
- 序号(从
0开始) - 节名称(
section_name) - 文件偏移
sh_offset - 大小
sh_size
- 序号(从
- 在遍历过程中,找到名字为
.symtab的节,并输出它在节头表中的序号(从0开始计算)。
输出格式
要求你的程序输出格式如下:
1 | section_count=<count> |
其中:
- 第一行
<count>为节头总数,即节头表表项的数量; - 最后一行
<index>为名称恰好等于.symtab的节头序号; - 从第二行起,
[i]表示第i个节头的信息;<offset>为该节的sh_offset,以小写十六进制输出,带0x前缀,不补前导零;<size>为该节的sh_size,按十进制输出;- 即使某个节名称为空字符串,也应正常输出。
输出节头信息的格式串请严格使用:
"[%d]\tname=\"%s\"\toffset=0x%lx\tsize=%lu\n"
样例输出 & 本地测试
你可以在本地通过如下方式测试:
$ cd tools/readelf64 $ make $ ./readelf64 hello
其输出应为:
1 | section_count=39 |
说明:
- 完整的样例输出已下发到
tools/readelf64/hello.txt文件中,供同学们参考。 - 评测时将根据需求使用不同的 ELF 文件进行测试,请不要依赖样例输出中的具体数值。
提交评测
请在开发机中执行下列命令后,在课程网站上提交评测:
$ cd ~/学号/ $ git add -A $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
评测标准
| 测试点序号 | 评测内容 | 分值 |
|---|---|---|
| 1 | 恰为样例 | 10 分 |
| 2 | 正确读取 ELF64 文件头,并输出 section_count |
20 分 |
| 3 | 正确输出所有节头的 name、offset 和 size |
40 分 |
| 4 | 正确找到 .symtab 输出 symtab_index |
20 分 |
| 5 | 所有输出内容完全正确 | 10 分 |
测试点依赖关系如下:
case:1case:2case:3case:4case:5
测试用例补充说明
- 所有测试文件均为 64-bit little-endian ELF 文件;
- 本题只涉及 ELF 文件头、节头表 和 节名称字符串表;
- 本题不要求解析程序头表,也不要求解析符号表项内容;
- 在线评测时,
tools/readelf64目录下的elf64_mini.h、hello、hello.txt、main.c、Makefile都可能被替换为标准版本,因此请不要在这些文件中编写实际功能所依赖的代码,也不建议对它们进行任何修改,以免丢失样例环境; elf64_mini.h仅保留了本题所需的最小结构体定义,请以此为主要参考。
补充提示
强烈建议 通过 回顾指导书/切换分支/复制文件 等方法,参考课下练习中 32 位版本 readelf 的实现思路来完成本题任务。
本题中所有 “序号” “索引” “下标” 等关键词,均从
0开始记。字符串比较 可以使用
string.h中的strcmp,函数原型为:int strcmp(const char *s1, const char *s2);当返回值为
0时,表示两个字符串相同;否则即两个字符串有差异。ELF 文件结构示意图(建议仔细参考)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42File Offset
(base)
base + 0x0000
+------------------------------------------------------------+
| ELF Header |
| e_shoff ---> 节头表起始偏移 |
| e_shnum ---> 节头表项数量 |
| e_shstrndx ---> 节名称字符串表对应节头下标 x |
+------------------------------------------------------------+
base + e_shoff
+------------------------------------------------------------+
| Section Header Table |
+------------------------------------------------------------+
| [0] |
+------------------------------------------------------------+
| [1] |
+------------------------------------------------------------+
| [2] |
+------------------------------------------------------------+
| ... |
+------------------------------------------------------------+
| [x] 节名称字符串表 .shstrtab 对应节头 |
| sh_name ---> 节名称在节名称字符串表中的偏移 |
| sh_offset ---> 节内容的文件偏移 |
| sh_size ---> 节大小 |
| ... |
+------------------------------------------------------------+
| [y] 符号表 .symtab 对应节头 |
| sh_name ---> 节名称在节名称字符串表中的偏移 |
| sh_offset ---> 节内容的文件偏移 |
| sh_size ---> 节大小 |
| ... |
+------------------------------------------------------------+
base + sh_table[x].sh_offset
+------------------------------------------------------------+
| 节名称字符串表内容 |
| "\0.text\0.data\0.bss\0.symtab\0.strtab\0.shstrtab\0..." |
| ↑ 各节头的 sh_name 都是在这张表中取字符串 |
+------------------------------------------------------------+若评测机反馈
运行时遇到错误 exit-code=139,请检查是否存在 非法内存访问(如访问了不属于该 ELF 文件的内存地址)。你可以通过gdb等工具进行调试,定位问题所在。
Lab 1 Extra
准备工作:创建并切换到 lab1-extra-off 分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab1-extra-off
初始化的 lab1-extra-off 分支基于课下完成的 lab1 分支,并且在 tests 目录下添加了 lab1_scan 样例测试目录。
题目背景
在操作系统内核中实现类似于 scanf 的格式化输入功能时,我们需要处理来自外部设备(如键盘、串口)的字符流。由于我们缺乏庞大的标准 C 库,你需要亲手实现一个精简版的格式化解析函数。
本题需要精准实现标准格式控制符(%c、%u、%s)对字符流的“吞吐行为”。 由于在解析变长数据(如读取数字和字符串)时,程序通常需要多读一个不属于该格式的字符才知道当前读取已经结束。因此,如何妥善保管这个“多读出来”的字符,不让它被丢弃,使得下一个格式符能继续正常解析,是本次实现的关键。
核心解析规则(务必仔细阅读)
你需要实现以下三种格式说明符。请严格遵循它们对“前导空白符”和“结束边界”的处理逻辑:
空白符定义:空格
' '、水平制表符\t、换行符\n、回车符\r。
%c(单字符)- 前导空白:绝不跳过。它会严格读取当前的下一个字符,无论是不是空白符。
- 结束边界:读取 1 个字符后立即结束。
- 状态要求:由于字符已被
%c实体消耗,你需要强制要求系统在下一次解析时重新去读取新字符(即将缓冲区置为无效)。
%u(无符号十进制整数)- 前导空白:必须跳过所有的前导空白符。
- 解析行为:匹配连续的数字(支持跳过前导加号
+,如+10解析为10)。如果遇到的第一个非空白字符就不是数字或+,直接赋值为0并结束。 - 结束边界:遇到第一个非数字字符时停止。
- 状态要求:导致停止的那个“非数字字符”必须原封不动地留在缓冲区中,等待下一个格式符处理。
- 数值范围:[0 , 2147483647) (小于
int范围)
%s(标准字符串)- 前导空白:必须跳过所有的前导空白符。
- 解析行为:连续读取非空白字符,并将其存入指针指向的内存中。
- 结束边界:遇到第一个空白符或
\0时停止,并在末尾自动补充\0封口。 - 状态要求:导致停止的那个“空白符”必须原封不动地留在缓冲区中,等待下一个格式符处理。
- 保证 0<字符串长度<20
你的任务(Task List)
请按顺序执行以下修改任务:
任务 1:添加头文件声明
在 include/printk.h 中加入以下声明(要加到#define _printk_h_和#endif /* _printk_h_ */的内部):
1 | // include/printk.h |
在 include/print.h 中加入以下声明(要加到#define _print_h_和#endif的内部):
1 | // include/print.h |
任务 2:实现顶层包装函数
在 kern/printk.c 中添加以下代码,实现字符流获取与 scan 的包装:
1 | // kern/printk.c |
任务 3:完成核心解析状态机
在 lib/print.c 中添加并补全以下代码。
注:骨架代码已经提供了单字节缓冲区 ch 和有效标志位 ch_valid 的定义,请利用它们完成【核心解析规则】中要求的行为逻辑。
1 | // lib/print.c |
样例输出 & 本地测试
对于下列样例:
1 | void mips_init(u_int argc, char **argv, char **penv, u_int ram_low_size) { |
其应当输出:
1 | === Basic Tests === |
你可以使用:
make test lab=1_scan && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=1_scan && make run在本地测试上述样例(开启优化)
调试提示
由于本题目存在与控制台交互(输入)的需求,使用 make dbg 目标进行 GDB 调试时,无法直接向 QEMU 控制台完成输入。在这里提示两种使用 GDB 调试本题目实现的方法:
使用
make dbg_pts与make connect目标进行调试在完成测试点编译后打开两个命令行窗口(可使用
tmux),先在其中一个执行make dbg_pts以启动 QEMU 并打开 GDB 调试界面,再在另一个终端中执行make connect连接到 QEMU 控制台进行测试输入。重定向 QEMU 终端输入
同学们也可以选择编辑
tools/run_bg.sh脚本,将脚本第五行改为$QEMU $QEMU_FLAGS -kernel $mos_elf <./test.txt -s -S >/tmp/qemu_stdout &即将原先的/dev/null替换为重定向的输入文件./test.txt。同学们只需在仓库根目录创建test.txt文件,并将测试输入写入其中即可(请注意,在测试输入末尾需要添加空白符标识输入结束)。注意,使用这种方式进行调试时,只可使用make dbg目标进行调试。
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
1 | $ cd ~/学号/$ git add -A |
具体要求和分数分布如下:
| 测试点序号 | 评测内容 | 分值 |
|---|---|---|
| 1 | 与题面中的样例相同 | 10 分 |
| 2 | 包含对 %c 基础格式的非混合评测 |
5 分 |
| 3 | 包含对 %u 基础格式的非混合评测(保证读取的数字之间有空格间隔) |
10 分 |
| 4 | 包含对 %s 基础格式的非混合评测(保证读取的字符串之间有空格间隔) |
10 分 |
| 5 | 包含对 %c 和 %u 相连格式的混合评测(不保证读取的字符串之间有空格间隔) |
15 分 |
| 6 | 包含对 %c 和 %s 相连格式的混合评测(不保证读取的字符串之间有空格间隔) |
20 分 |
| 7 | 综合组合评测 | 30 分 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5case:6case:7
测试用例补充说明:
- 对于第一个测试点,其测试内容不包含样例外的任何其他内容。
- 对于后四个测试点,测试数据可能会包含任何题面中要求实现的功能变体及混合组合。
- 在线评测时,所有的
.mk文件、所有的Makefile文件、init/init.c以及tests/和tools/目录下的所有文件都可能被替换为标准版本,因此请同学们本地开发时,不要在这些文件中编写实际功能所依赖的代码。
Lab 2 Exam
准备工作:创建并切换到 lab2-exam-off 分支
基于已完成的 lab2 提交自动初始化 lab2-exam 分支
在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab2-exam-off
初始化的 lab2-exam-off 分支基于课下完成的 lab2 分支,并且在 tests 目录下添加了 lab2_list_insert_at 样例测试目录。
题目背景 & 题目描述
在操作系统内核中,双向链表(如 <queue.h> 中定义的 LIST 系列宏)被广泛应用于物理内存页管理、进程控制块队列等重要数据结构的维护。现有的链表宏提供了头部插入(LIST_INSERT_HEAD)、在特定元素前后插入(LIST_INSERT_AFTER / LIST_INSERT_BEFORE)等功能。
在某些特定的调度或分配场景下,我们需要将一个元素插入到链表的特定索引位置。在本题中,你需要实现一个新的 C 语言宏 LIST_INSERT_AT,将指定的元素插入到给定链表的第 index 个位置。
#define LIST_INSERT_AT(type, head, elm, field, index)
该宏各参数的意义与具体功能描述如下:
通过调用此宏,将元素 elm 插入到链表 head 的第 index 个位置(索引从 0 开始)。
type:链表节点对应的结构体类型名(例如Page)。head:指向链表头部的指针。elm:待插入的元素指针。field:结构体中用于链接的LIST_ENTRY字段名(例如pp_link)。index:目标插入位置的索引。- 如果
index == 0,则将elm插入到链表的最头部,使其成为链表新的首个元素(即第0个元素)。 - 如果
index > 0,则将其插入到原链表第index - 1个元素的后面。 - 测试样例保证传入的
index大于等于 0 且小于等于当前链表的长度(当index等于链表长度时,意味着将元素追加到链表最尾部)。 - 测试样例保证传入的
index表达式不存在副作用。
- 如果
题目要求
在 include/queue.h 中添加 LIST_INSERT_AT 宏的定义。
提示
- 本题要求使用宏实现,不能使用普通的 C 函数。在评测中,测试代码可能会将不同的类型名(如
Page)作为参数传入,普通函数无法接收类型名作为参数。 - 可以组合使用已有的链表宏。例如:
- 当
index == 0时,可以直接调用LIST_INSERT_HEAD。 - 当
index > 0时,可以使用LIST_FOREACH宏配合自定义的计数器遍历链表,找到对应的节点后使用LIST_INSERT_AFTER插入。
- 当
- 注意 C 语言宏的安全编程规范:
- 宏的外部应使用
do { ... } while (0)包裹以保证语法的安全性。 - 宏内部使用传入的参数时,建议加上括号(如
(index)),防止表达式优先级导致的逻辑错误。 - 宏内部声明临时变量时(如计数器变量或迭代指针),建议使用带有下划线前缀的命名(如
_cnt,_var),以防止与外部作用域的变量名发生冲突。
- 宏的外部应使用
- 评测会借助课下已给出的
include/queue.h中的相关链表宏,请保证没有对官方代码进行魔改。
样例输出 & 本地测试
对于以下样例:
1 |
|
其应当输出:
1 | test succeeded! |
你可以使用:
make test lab=2_list_insert_at && make run 在本地测试上述样例(调试模式)
MOS_PROFILE=release make test lab=2_list_insert_at && make run 在本地测试上述样例(开启优化)
或者在 init/init.c 的 mips_init 函数中自行编写测试代码并调用 test_list_insert_at() 使用 make && make run 测试。
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
1 | $ cd ~/学号/ |
测试点说明及分数分布如下:
| 测试点序号 | 评测说明 | 分值 |
|---|---|---|
| 1 | 与样例相同 | 10 分 |
| 2 | 仅测试基于空链表及非空链表的头部插入 (index == 0) |
20 分 |
| 3 | 仅测试在链表中间位置的插入 (0 < index < length) |
25 分 |
| 4 | 仅测试在链表末尾追加元素 (index == length) |
25 分 |
| 5 | 综合评测 | 20 分 |
Lab 2 Extra
准备工作:创建并切换到 lab2-extra-off 分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab2-extra-off
初始化的 lab2-extra-off 分支基于课下完成的 lab2 分支,并且在 tests 目录下添加了 lab2_selfmap 样例测试目录。
题目背景
自映射是我们 MOS 中的一大特色,也是理论考试中经常会出现的重难点。在本次实验中,我们将会通过一段简单的讲解,以及一道有趣的题目,带大家深入理解自映射的作用、原理和实现方法。
如果你确信自己已经充分理解了自映射,那么可以跳过本章的内容,直接阅读题目描述一章。
我们知道,在 MOS 的两级页表设计中,每个进程将 1 个 4 KB 的页面作为页目录,页目录中有 1024 个 4 Bytes 的页目录项,分别指向 1024 张页表。每张页表依然占据 1 个 4 KB 的页面,每张页表中有 1024 个 4 Bytes 的页表项,分别指向 1024 个物理页面。这样,我们就能够通过页表查询到 1024 * 1024 * 4KB = 4GB ,即 32 位的虚拟地址空间对应的物理页面。
在目前的 MOS 中,我们只能通过访问 kseg0 段的虚拟地址来访问页表,这就限制了我们只能在内核态访问它们。在之后的实验中,我们希望能够在用户态以只读的模式访问到页表,这样就可以将许多本来需要在内核态才能完成的操作移至用户态,体现微内核的思想。同时,不允许在用户态修改页表的内容,也保证了操作系统内核的安全。
那么,如果我们想要在用户态读取到页表中的内容,就需要使用 kuseg 段的虚拟地址与页表的物理页面之间建立映射。于是我们考虑划出一个 1024 * 4KB = 4MB 大小的虚拟地址空间,将其依次与 1024 张页表建立映射。我们假设这段虚拟地址是 [0x7fc00000, 0x80000000) ,于是它们的映射关系如下图所示:
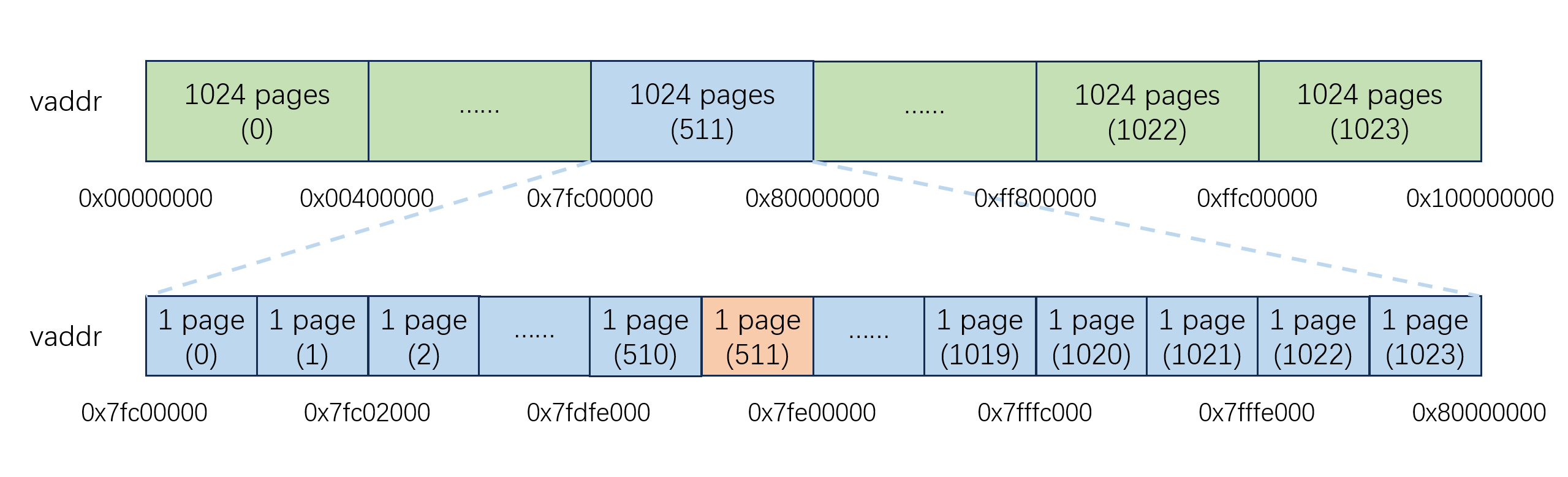
(如果你无法准确分辨图片中的颜色,请及时联系助教,助教可以帮你指出图中的颜色)
图中上方的条形图为整个 4GB 的虚拟地址空间,其中蓝色的方块代表着 1024 张页表对应的 4MB 虚拟地址空间。我们将这部分虚拟空间放大来看,就得到了下方的条形图,其中每个方块代表着 1 张页表对应的 4KB 虚拟地址空间。
我们来分析一下此时该如何通过 kuseg 段虚拟地址访问到任意页表。我们首先给出要访问的页表的虚拟地址,显然这个虚拟地址一定位于 [0x7fc00000, 0x80000000) 范围内,即 4GB 虚拟地址空间中的第 511 个 4MB 虚拟地址空间(从 0 计数,下同),于是我们找到页目录(图中金色的部分)中的第 511 条页目录项,并据此找到第 511 张页表(图中橙色的部分)。
接下来根据要访问的页表在 kuseg 段的虚拟地址,我们在橙色页表中寻找对应的页表项,并据此找到对应的页表。假设我们要访问的是第 1 张页表,那么上述过程就如下图红色箭头所示:
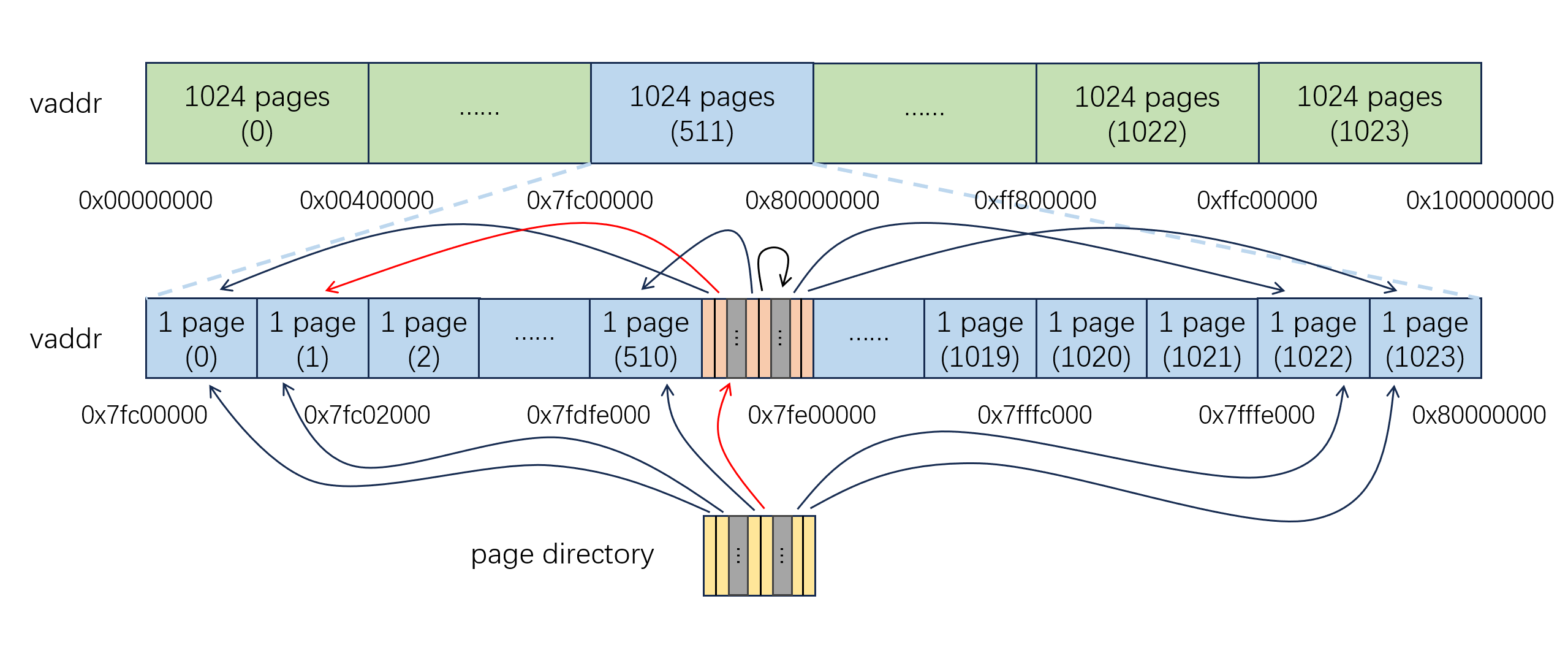
我们知道,操作系统在启动的时候不会一次性创建全部的 1024 张页表,而是在程序运行的过程中动态创建。从上述过程中我们能够看出,如果需要创建一个新页表,我们原本只需要维护页目录中指向新页表的页目录项,现在则还需要再维护橙色页表中指向新页表的页表项,这样才能够保证我们可以使用 kuseg 段虚拟地址访问到页表。然而从上图中我们可以看出,页目录和橙色页表的所有表项实际上都是完全相同的,于是我们就可以直接用页目录替换掉橙色页表,这就是所谓的自映射:
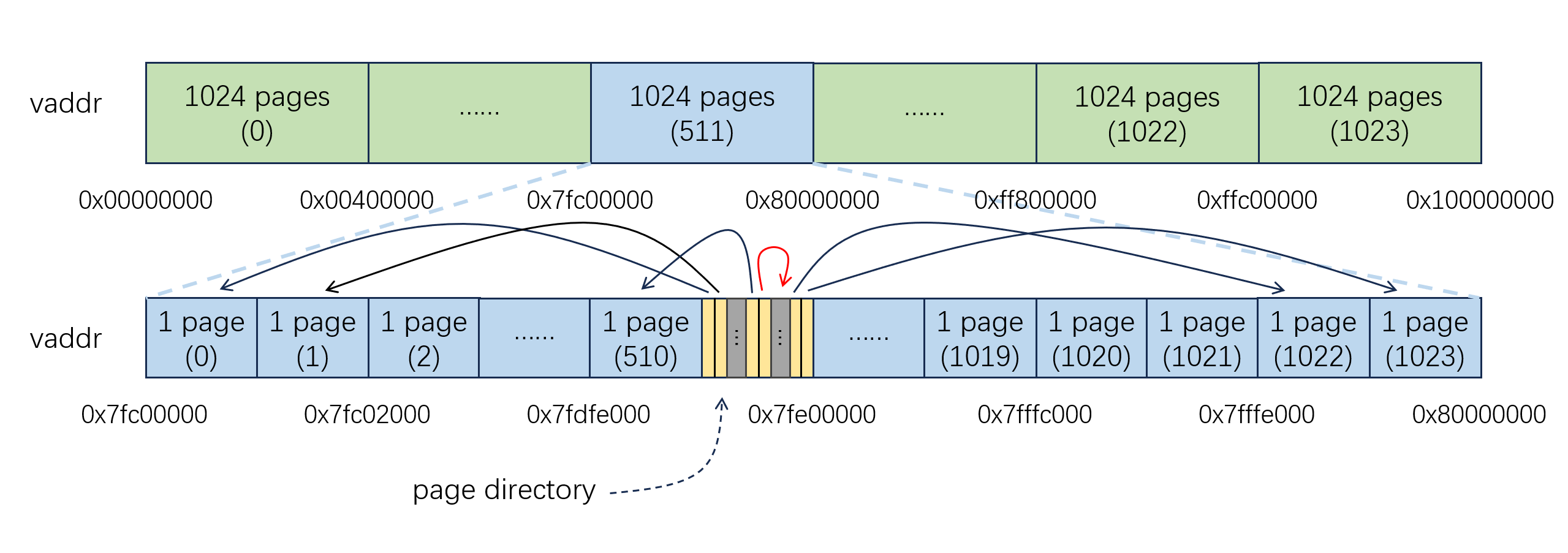
在之前的设计中,页目录的第 511 条页目录项指向橙色页面。经过替换之后,页目录的第 511 条页目录项就指向了自己。也就是说,这个页面既是页目录,又是 1024 张页表中的第 511 张页表,真的是太美妙了!
到这里,相信你已经充分理解了自映射的含义,让我们开始接下来的挑战吧!
提示:在使用页目录替换掉橙色页表之后,我们就不再需要额外维护原本橙色页表中的页表项了。不过,在建立自映射的时候,你还需要额外维护 1 个页目录项,以确保页目录的某条表项指向自己。
题目描述
在本题中,你需要在 MOS 中模拟自映射的建立、查询与解除。具体来说,你需要实现 create_self_map() pte_va() pde_va() remove_all_self_map() 4 个函数。
自映射的建立
create_self_map() 函数的功能为:给定页目录首地址 pgdir 和 asid ,将所有页表自映射至 [base, base + 1024 * PAGE_SIZE) 的连续 4MB 虚拟地址空间。你可以参考如下实现流程:
- 遍历
[base, base + 1024 * PAGE_SIZE)的虚拟地址,检查其是否已经与物理页面建立了映射。如果已经建立了映射,则使用page_remove()函数解除映射,并使用计数变量count记录已经解除的映射数量; - 将所有页表自映射至
[base, base + 1024 * PAGE_SIZE)的地址空间。这里要注意的是,你需要手动为页目录项加上合适的权限位,保证其有效且不可写,如果你在实现这一步时遇到了困难,请仔细阅读题目背景一章的内容; - 返回计数变量
count的值。
自映射的查询
pte_va() 函数的功能为:给定自映射虚拟地址空间的首地址 base ,计算使用自映射访问第 pdeno 张页表的第 pteno 个页表项时,需要使用的虚拟地址。
pde_va() 函数的功能为:给定自映射虚拟地址空间的首地址 base ,计算使用自映射访问页目录中的第 pdeno 个页目录项时,需要使用的虚拟地址。
这两个函数请你根据对自映射的理解自行实现,在这里不给出过多的提示。使用合适的位运算,你可以分别使用一行代码完成这两个函数。
自映射的解除
remove_all_self_map() 函数的功能为:给定页目录首地址 pgdir 和 asid ,解除当前已经建立的所有自映射。你可以参考如下实现流程:
- 遍历所有页目录项,找到其中用于实现自映射的表项,将表项清空以解除自映射,并使用计数变量
count记录已经解除的自映射数量,如果你在实现这一步时遇到了困难,请仔细阅读题目背景一章的内容; - 通过上述表项的地址相对于页目录首地址的偏移,计算自映射虚拟地址空间的首地址
base; - 对于每一个解除的自映射,遍历
[base, base + 1024 * PAGE_SIZE)的虚拟地址,清空其在 TLB 中的缓存; - 返回计数变量
count的值。
提示 & 注意事项
- 在整道题目中,我们均不考虑页控制块(即
Page结构体)中pp_ref字段的变化。 - 由于我们尚未实现进程管理与用户态,在本题中,我们认为整个操作系统中只存在 1 张页目录,其基地址即为函数中的参数
Pde *pgdir。另外注意,请不要使用cur_pgdir这个全局变量。 - 在测试数据中,我们保证不会出现两次自映射虚拟地址空间相同的情况。不过在自映射解除之后,其虚拟地址依然有可能与其它物理页面建立映射,你需要维护好 TLB 表项。
- 在测试数据中,我们保证
pgdir为正确的页目录首地址,保证asid为 0 到 255 之间的整数,保证base在 kuseg 段范围内且为 1024 * PAGE_SIZE 的倍数,保证pdeno和pteno为 0 到 1023 之间的整数。
实验提供代码
请将本部分提供代码附加在你的 include/pmap.h 中:
1 | int create_self_map(Pde *pgdir, u_int asid, u_long base); |
请将本部分提供代码附加在你的 kern/pmap.c 的尾部,然后开始完成题目。
1 | int create_self_map(Pde *pgdir, u_int asid, u_long base) { |
本地测试说明
你可以使用:
make test lab=2_selfmap && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=2_selfmap && make run在本地测试上述样例(开启优化)
或者在 init/init.c 的 mips_init 函数中自行编写测试代码并使用 make && make run 测试。
如果样例测试中输出了如下结果,说明你通过了本地测试。
Congratulations! You passed the local test!
提示:本地测试为综合测试,即使无法通过本地测试,只要有部分功能是正确的,也有可能通过线上评测的部分测试点,请积极尝试提交,尽量提高自己的分数!
提交评测
请在开发机中执行下列命令后,在课程网站上提交评测。
1 | $ cd ~/学号/ |
评测说明
评测时使用的 mips_init() 函数示意如下:
1 | void mips_init() { |
test_selfmap() 函数会被测试文件中的函数替代,请不要修改其中的内容。
具体要求和分数分布如下:
| 测试点序号 | 评测说明 | 分值 |
|---|---|---|
| 1 | 检查 pte_va() 函数和 pde_va() 函数的计算结果 |
30 |
| 2 | 检查 create_self_map() 函数中原有映射的解除与自映射的建立 |
20 |
| 3 | 检查 remove_all_self_map() 函数中自映射的解除与 TLB 的维护 |
20 |
| 4 | 检查 create_self_map() 函数和 remove_all_self_map() 函数的返回值 |
10 |
| 5 | 综合测试 | 20 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5
Lab 3 Exam
准备工作:创建并切换到 lab3-exam-off 分支
请在自动初始化分支后,在开发机上依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab3-exam-off
初始化的 lab3-exam-off 分支基于课下完成的 lab3 分支,并且在 tests 目录下添加了 lab3_SRTF 样例测试目录。
题目描述
课下我们在 MOS 系统中实现了时间片轮转算法(Round-Robin,RR)用于进程调度。在本题中,我们将实现抢占式短作业优先(Shortest Remaining Time First, SRTF),用于调度特定任务进程。
题目要求
在本题中,你需要实现函数 env_create_srtf 用于创建 SRTF 调度进程,并返回指向被创建进程的进程控制块的指针。该函数声明如下:
struct Env *env_create_srtf(const void *binary, size_t size, int runtime);
其中,参数 binary、size 与 env_create 函数中的定义相同,runtime 为 SRTF 调度参数,以时间片为单位:runtime 表示进程总共需要运行的时间片数量。
在本题中,我们将 MOS 系统两次时钟中断之间的间隔定义为一个时间片。
对于每个使用 env_create_srtf 创建的进程,你需要使用 SRTF 算法来进行调度(详见调度规则和示例)。
调度规则
新增的 SRTF 算法与 MOS 原有的 RR 算法拥有各自独立的调度队列。SRTF 调度队列中包含所有使用
env_create_srtf创建的进程,而 RR 调度队列(MOS 原有的调度队列)中包含所有使用env_create创建的进程。当时钟中断产生时,若 SRTF 调度队列中存在尚未运行完所需时间片(
runtime)的进程,则选取其中剩余运行时间最少的进程调度。如果多个进程的剩余运行时间相同,则选择env_id最小的进程调度。从 SRTF 调度队列选取进程后,你仅需使其运行一个时间片,并在下个时钟中断产生时根据第二条规则,重新选择进程调度。本题中要实现的 SRTF 调度算法不受
yield参数和进程优先级的影响,只与进程的剩余运行时间有关。如果 SRTF 调度队列为空,或其中的所有进程均已运行完所需的时间片(即剩余运行时间为 0),则使用课下实现的 RR 算法调度 RR 调度队列中的进程。需要注意的是,SRTF 调度的进程可以在任何时刻抢占 RR 调度的进程,且 RR 调度的进程运行的时间片在被 SRTF 抢占后不发生变化。例如,如果 RR 算法选择调度一个优先级为 5 的进程 A,并已经使其运行了 3 个时间片,此时 SRTF 队列中产生了可以被调度的进程 B,则进程 B 会抢占进程 A 的运行,直至进程 B 及其它 SRTF 进程运行完毕,SRTF 队列为空或所有进程均结束,进程 A 继续运行剩余的 2 个时间片。
示例
以下示例展示:SRTF 进程中途抢占 RR 进程,以及 SRTF 全部结束后恢复 RR 调度。
| 进程名 | 类型 | 优先级 | Runtime | 创建时机 |
|---|---|---|---|---|
| A | RR | 5 | - | 初始创建 |
| B | RR | 1 | - | 初始创建 |
| C | SRTF | - | 2 | 第 3 个时间片后创建 |
初始时只有 RR 队列,且当前正在运行 A。
- 第 0-2 个时间片:SRTF 队列为空,按 RR 调度 A。A 已运行 3 个时间片,还剩 2 个 RR 时间片。
- 第 3 个时间片后:创建 SRTF 进程 C(runtime=2)。
- 第 4 个时间片:到达下一次调度点,C 抢占 A。C 剩余时间 2 -> 1。
- 第 5 个时间片:继续调度 C。C 剩余时间 1 -> 0,C 运行完毕并移出 SRTF 调度队列。
- 第 6 个时间片及以后:SRTF 队列再次为空,恢复 RR 调度。A 继续运行其剩余的 2 个时间片(不会重置为 5);A 用完后再按 RR 规则调度 B。
参考实现思路
本参考实现基于LIST结构,你也可以采取 TAILQ 结构来实现,满足题目要求即可。
本题参考实现思路如下,你也可以采取其它思路,满足题目要求即可。
- 在
include/env.h中添加以下声明:
1 | LIST_HEAD(Env_srtf_sched_list, Env); |
- 在
kern/env.c中添加env_srtf_sched_list的定义,并在env_init函数中初始化env_srtf_sched_list。
struct Env_srtf_sched_list env_srtf_sched_list; // SRTF 调度队列
在
include/env.h的Env结构体中添加以下字段:1
2
3LIST_ENTRY(Env) env_srtf_sched_link; // 构造 env_srtf_sched_list 的链表项
u_int env_total_runtime; // SRTF 调度参数:进程总共需要运行的时间片
u_int env_runtime_left; // 进程剩余需要运行的时间片在
kern/env.c中仿照env_create实现env_create_srtf函数,其中需要初始化进程控制块的相关字段,参考如下:1
2
3
4
5
6
7struct Env *env_create_srtf(const void *binary, size_t size, int runtime) {
...
// 分配 env 并初始化
// ...
// 处理新增的字段
return e;
}修改
kern/sched.c中的schedule函数,实现 SRTF 调度算法。
1 | void schedule(int yield) { |
提示
你可以使用
LIST_FOREACH宏遍历队列。为了保证 RR 调度的连续性,当 SRTF 抢占结束后,RR 算法应该从上次被抢占的地方继续运行。可能需要一个静态变量
struct Env *last_rr_env来记录上一次 RR 调度的进程。static变量在程序运行期间仅在第一次遇到时初始化一次,且函数被多次调用时不会重新初始化该变量,因此适合作为跨调用保存状态(例如记录上一次被 RR 调度的进程)。
评测说明
- 测试程序将调用
env_create和env_create_srtf创建一批进程。 env_free不会被测试。- 评测保证不会出现死锁或空队列情况。
- 在评测中,我们保证进程运行完 main 函数后自动进入死循环,而不会主动退出(详见测试目录下的 entry.S 文件)。因此,env_destroy、env_free 函数不会被调用,你无需对它们进行修改。你可以据此结合提示,简化你的实现。
- 不保证进程创建的时机
- 评测中保证不会出现 SRTF 调度队列中无可调度进程且 RR 调度队列为空的情况。
- 对于SRTF调度的进程,可能耗完时间片后程序仍然未结束运行,(例如样例中的 test_hash3 和 test_hash4),此时它们会被移出 SRTF 调度队列,不需要额外的处理,你的实现只需保证它们的调度正确即可。
本地测试说明
测试样例如下:
1 |
|
你可以使用:
make test lab=3_srtf && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=3_srtf && make run在本地测试上述样例(开启优化)
运行若干时间片后,前 7 个时间片应为 SRTF 进程运行(先 2 个 hash4, 后 5 个 hash3)。之后 SRTF 队列为空,转为 RR 调度,按优先级依次运行 hash2 (优先级 3) 和 hash1 (优先级 1)。
1 | 0: 00002003 |
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
$ cd ~/学号 $ git add -A $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
在线评测时,所有的 .mk 文件、所有的 Makefile 文件、init/init.c 以及 tests/ 和 tools/ 目录下的所有文件都可能被替换为标准版本,因此请同学们在本地开发时,不要在这些文件中编写实际功能所依赖的代码。
具体要求和分数分布如下:
| 测试点序号 | 评测说明 | 分值 |
|---|---|---|
| 1 | 与样例相同 | 15 |
| 2 | 混合创建进程测试,仅在初始化时创建进程 | 20 |
| 3 | 所有进程均使用 env_create_srtf 创建 |
15 |
| 4 | 不保证进程创建时机 | 15 |
| 5 | 综合测试 | 35 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5
Lab3 Extra
准备工作:创建并切换到 lab3-extra-off 分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab3-extra-off
初始化的 lab3-extra-off 分支基于课下完成的 lab3 分支,并且在 tests 目录下添加了 lab3-bp 样例测试目录。
问题描述
课下实验中,我们主要介绍了异常的分发、异常向量组和 0 号异常(时钟中断)的处理过程。在本次 Extra 中,我们希望大家拓展 9 号 Bp 异常的异常分发,并在此基础上实现自定义的异常处理。
Bp异常(Breakpoint)由break指令触发,在 MIPS 指令集中,对该异常的描述如下:
| ExcCode | 助记符 | 描述 |
|---|---|---|
| 9 | Bp | 执行 Break 指令 |
break 指令用于软件断点,其机器码格式如下:
| 31-26(op) | 25-6(code) | 5-0(funct) | 格式 |
|---|---|---|---|
| 000000 | code (20 bits) | 001101 | break code |
其中 op 字段恒为 0,funct 字段恒为 0x0d,而 code 字段是一个 20 位的立即数,可用于传递不同的参数。
在本次题目中,我们要实现自定义的 Bp 异常处理,根据 code 的不同取值执行不同的操作:
若
code == 0x0,表示用户断点,直接退出异常处理,继续执行后续指令。若
code == 0x6,数组访问越界触发,程序会将数组长度存入$a0(4号寄存器),要求对访存指令(当前break指令的下一条指令)的立即数(imm)部分进行检查和修改,对应索引为(imm >> 2):- 若越界的索引为负数,则将立即数设置为0。
- 若越界的索引大于等于数组长度,则修改立即数,使得索引为数组长度减1,即数组的最后一个元素。
越界检查格式如下:
... // 数组长度存入$a0 break 6 lw/sw $t2, imm(base)base是数组首地址,imm立即数是索引。若
code == 0x7,除零异常触发,要求获取将要发生错误的除法指令(当前break指令的下一条指令),并且修改除数为2。除零检查格式如下:
bne $9, $zero, div_ok break 7 div_ok: div $8, $9
div,lw,sw指令的机器码如下:
| 指令 | 31-26(op) | 25-21 | 20-16 | 15-11 | 10-6 | 5-0(funct) |
|---|---|---|---|---|---|---|
| div | 000000 | rs(被除数) | rt(除数) | 00000 | 00000 | 011010 |
| 指令 | 31-26(op) | 25-21 | 20-16 | 15-0 |
|---|---|---|---|---|
| lw | 100011 | base | rt | imm |
| sw | 101011 | base | rt | imm |
在异常处理完成,返回用户态之前,需要输出相应信息:
用户断点
printk("Break skip!\n");越界检查
printk("Out of bounds handled, new imm is : %04x!\n", new_imm); // new_imm为替换后的立即数除零检查
printk("Divide by zero handled!\n");
注意:在异常处理结束前,必须让 EPC 指向下一条指令,否则会反复触发 Bp 异常。如果你的异常处理程序运行超时,请检查该步骤是否实现正确。
题目要求
- 建立
Bp异常的处理函数。 - 完成异常的分发,将 9 号异常绑定到该处理函数。
- 在处理函数中,根据 break指令中的
code字段实现上述三种分支,并输出相应信息。
提示
在
kern/genex.S中,用BUILD_HANDLER宏来构建异常处理函数(切勿添加到 if 中):1
2
3
4
5
6
7
BUILD_HANDLER mod do_tlb_mod
BUILD_HANDLER sys do_syscall
BUILD_HANDLER reserved do_reserved
BUILD_HANDLER bp do_bp在
kern/traps.c修改异常向量组,并实现异常处理函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 声明 handle 函数
extern void handle_bp(void);
// exception_handlers 请按以下代码实现
void (*exception_handlers[32])(void) = {
[0 ... 31] = handle_reserved,
[0] = handle_int,
[2 ... 3] = handle_tlb,
[9] = handle_bp,
[1] = handle_mod,
[8] = handle_sys,
};
void do_bp(struct Trapframe *tf) {
/* 1. 获取 break 指令及其 code */
/* 2. 分类处理异常 */
switch (code) {
case 0x0:
// 处理用户断点
break;
case 0x6:
// 处理索引越界
break;
case 0x7:
// 处理除数为零
break;
}
return;
}在完成处理函数时:
本题涉及对寄存器值的读取和修改。你需要访问或修改保存现场的
Trapframe结构体(定义在include/trap.h中)中对应通用寄存器。本题涉及到对内存的访问。
可以通过EPC寄存器增减4获取当前指令的前后指令的虚拟地址。
由于我们要修改的指令部分在 kuseg 区间,这一部分的虚拟地址需要通过 TLB 来获取物理地址。我们设置了程序中保存操作指令代码的.text节权限为只读,这部分空间在页表中仅被映射为 PTE_V,而不带有 PTE_D 权限,因此经由页表项无法对物理页进行写操作。可以考虑查询 curenv 的页表获取对应指令的物理地址,再转化为 kseg0的虚拟地址,从而修改相应内容。
因为本题中对内存访问较多,建议构造虚拟地址转化到内存中指令地址的功能辅助函数。
1
2
3
4
5
6int *va2instrAddr(unsigned long va) {
/* 1. 查询 curenv 的页表获取虚拟地址对应页表项; */
/* 2. 通过页表项和虚拟地址得到物理地址; */
/* 3. 将该物理地址转化为 kseg0 区间中虚拟地址; */
/* 可能会使用到的函数和宏:page_lookup, PTE_ADDR, KADDR */
}
可以通过更改 CP0 中 EPC 寄存器(对应
Trapframe结构体中的成员cp0_epc)的值,使得异常恢复后执行的是下一条指令。
MIPS中,lw/sw要求地址4字节对齐。从指令立即数提取字索引时,需右移2位恢复原值;以字为单位的数组索引访问时,需左移2位转换为字节偏移。立即数不保证为正数,你需要对16位立即数的符号位进行维护(例如使用16位有符号类型short存储立即数)。
题目约束
- 测试程序
Bp异常只会出现code为 0x0,0x6 和 0x7 这三种情况,不会出现其他值。 - 测试保证所有越界异常的
break指令,base寄存器一定不是4号寄存器,base中存储的是数组首地址。不保证lw和sw指令的立即数为正数。 - 测试保证所有
div指令都会进行除零检测且只会因为除零陷入Bp异常,break指令一定是除法指令的前一条指令。除法指令只会出现div,且不会发生宏展开,不会发生除法溢出。 - 本题保证发生
Bp异常的指令的上一条指令不会是任意跳转指令,即保证发生Bp异常的指令不会出现在延迟槽中。
样例输出 & 本地测试
本地测试样例如下:
1 |
|
你可以使用:
make test lab=3_bp && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=3_bp && make run在本地测试上述样例(开启优化)
运行正确的结果应当如下:
1 | Break skip! |
注:如果要本地构建样例测试,由于break的机器码在 GNU 中与 Mips 不同,请使用 .word ((<code> << 6) | 0x0d) 代替 break code 进行样例构造。你也可以使用样例提供的宏定义进行测试
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
$ cd ~/学号 $ git add -A $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
在线评测时,所有的 .mk 文件、所有的 Makefile 文件、init/init.c 以及 tests/ 和 tools/ 目录下的所有文件都可能被替换为标准版本,因此请同学们在本地开发时,不要在这些文件中编写实际功能所依赖的代码。
具体要求和分数分布如下:
| 测试点序号 | 测试点内容 | 测试点分值 |
|---|---|---|
| 1 | 样例 | 10分 |
| 2 | 仅有 code = 0x0 的 Bp异常 |
10分 |
| 3 | 仅有 code = 0x6 的 Bp异常 |
30分 |
| 4 | 仅有 code = 0x7 的 Bp异常 |
20分 |
| 5 | 多种 code 混合的 Bp异常 |
30分 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5
Lab 4 Exam
准备工作:创建并切换到 lab4-exam-off 分支
请在自动初始化分支后,在开发机依次执行以下命令:
cd ~/学号 git fetch git checkout lab4-exam-off
初始化的 lab4-exam-off 分支基于课下完成的 lab4 分支,并且在 tests 目录下添加了 lab4_systrace 样例测试目录。
题目背景
在实现系统调用时,除了需要保证功能正确之外,我们还希望确认:一个普通系统调用,是否真的按照 “用户态包装函数 → msyscall → 内核分发 → sys_* → 返回用户态” 的整体链路被正确执行。
本题围绕 MOS 的页面管理机制,要求各位同学新增一个双参数系统调用,用于查询两个虚拟地址对应页面的物理页引用计数,并返回一个组合结果。该系统调用本身并不复杂,但能够覆盖一条完整的普通系统调用链路,并检验各位同学是否真正理解:
- 当前进程地址空间中的虚拟页与物理页映射关系;
- 物理页引用计数
pp_ref的含义; - 普通系统调用的参数传递与返回值传递过程。
本题不涉及页写入异常、TLB Mod、COW、异常处理栈、IPC、fork 等内容,大家不需要考虑的太过复杂。
任务:新增系统调用 sys_trace_ref2
你需要添加一个系统调用:
int sys_trace_ref2(u_int a, u_int b);
对于该系统调用的返回值,我们首先定义一个辅助函数 ref(x),其中 x 是一个虚拟地址,ref(x) 的定义如下:
- 若
x不属于当前进程的合法用户地址范围,则ref(x) = -E_INVAL; - 若
x属于合法用户地址范围,但其所在页在当前进程地址空间中不存在有效映射,则ref(x) = 0; - 若
x对应页面已映射,则ref(x)等于该物理页的引用计数pp_ref。
则该系统调用的返回值定义为:
ref(a) + 2 * ref(b)
实现参考
你需要修改如下位置:
- 在
include/syscall.h中新增一个枚举值SYS_trace_ref2; - 在
kern/syscall_all.c中增加一个系统调用实现,并将其注册到syscall_table中:
int sys_trace_ref2(u_int a, u_int b) { ... }
- 在
user/include/lib.h中增加一个用户态系统调用声明:
int syscall_trace_ref2(u_int a, u_int b);
- 在
user/lib/syscall_lib.c中增加它的具体实现,你可以通过msyscall发起系统调用。
注意事项
- 请确保用户态函数名为
syscall_trace_ref2,系统调用号名称为SYS_trace_ref2; - 该系统调用共有 2 个参数,每个参数都代表一个虚拟地址,对于每个虚拟地址,请注意区分题目要求的三种情况;
- 查询虚拟地址
va对应物理页的引用计数时,可先在当前进程页表中查找va是否已映射到某个物理页,若查找到对应页,再读取该物理页描述结构中的引用计数字段即可; - 判断地址是否合法时,可以结合 MOS 的地址空间布局来考虑,我们这里将小于
ULIM的地址视为合法用户地址范围,其中ULIM是用户空间与内核空间的边界;因此,本题中合法用户地址的上界应当取为ULIM; - 该系统调用查询的是当前进程地址空间,因此不需要传入
envid; - 该系统调用没有副作用,只用于校验系统调用链路中的参数传递、页查询逻辑和返回值传递是否正确,大家在实现的时候不需要考虑的太复杂。
样例输出与本地测试
有如下用户程序样例:
1 |
|
应当输出:
1 | ^_^ init_uu = 0 |
你可以使用:
make test lab=4_systrace && make run
在本地测试上述样例(调试模式),或者使用:
MOS_PROFILE=release make test lab=4_systrace && make run
在本地测试上述样例(开启优化)。
样例说明
本题所有测试都围绕同一个系统调用 sys_trace_ref2 展开,评测数据会从不同角度检查:
- 该系统调用从用户态到内核态的链路是否正确;
- 当前进程页表中的映射查询逻辑是否正确;
- 非法地址、未映射地址、已映射地址三种情况是否被正确区分。
请注意,本题测试的评测数据可能不仅会通过你写好的用户态包装函数发起系统调用,也可能会直接通过 msyscall 校验系统调用号、参数传递和内核分发过程。因此,你需要确保:
- 系统调用号正确;
- 用户态包装函数正确;
- 内核中的系统调用实现正确;
syscall_table中的分发正确。
提交评测与评测标准
请在开发机中执行下列命令后,在课程网站上提交评测:
cd ~/学号 git add -A git commit -m "message" # 请将 message 改为有意义的信息 git push
在线评测时,所有的 .mk 文件、所有的 Makefile 文件、init/init.c 以及 tests/ 和 tools/ 目录下的所有文件都可能被替换为标准版本,因此请不要在这些文件中编写实际功能所依赖的代码。
测试点和分数说明
| 测试点序号 | 评测内容 | 分数 |
|---|---|---|
| 1 | 弱测:和样例完全相同。 | 10 |
| 2 | 弱测:检查 SYS_trace_ref2 的基本计算功能,不涉及边界判断。 |
20 |
| 3 | 中测:检查 SYS_trace_ref2 的基本计算功能,不涉及边界判断。 |
20 |
| 4 | 强测:检查 SYS_trace_ref2 在边界值、非法或未映射地址、页内与跨页访问下的行为。 |
20 |
| 5 | 强测:综合检查 SYS_trace_ref2 在动态映射变化下的整体行为与结果一致性。 |
30 |
测试点依赖关系
箭头方向表示依赖方向。
case1-sample-testcase2-weak-trace_ref2-basiccase3-mid-trace_ref2-normalcase4-strong-trace_ref2-edgecase5-strong-trace_ref2-full
Lab 4 Extra
准备工作:创建并切换到 lab4-extra-off 分支
请在自动初始化分支后,在开发机依次执行以下命令:
$ cd ~/学号 $ git fetch $ git checkout lab4-extra-off
初始化的 lab4-extra-off 分支基于课下完成的 lab4 分支,并且在 tests 目录下添加了lab4_dirty_page_sample 样例测试目录。
提示:本题测试点独立性相对较高,且不依赖样例。若未完全实现,也可以提交以获得部分分数。
题目背景
在现代操作系统中,内存管理不再局限于物理页的分配与映射,正转向对程序内存访问行为的精细化监控与追踪。其中,“脏页追踪”是一项被广泛应用的底层技术。
所谓“脏页”,是指在某一段特定时间内,被应用程序写入或修改过的内存页面。掌握脏页记录意味着系统能精确追踪内存的变动,这种机制在一些领域有所应用:在云计算场景中,虚拟机热迁移时,它用于获取迁移期间的内存修改,并同步至目标机器;而在后续的文件系统实验中,它可以用于识别缓存中的修改内容,确保在关闭文件时能准确地将数据持久化到磁盘。
在本题目中,你需要结合 Lab4 课下实验中的系统调用机制、写时复制机制、页写入异常等知识点,在 MOS 中实现脏页记录功能。
要求实现的功能如下图所示,你可以右键单击该图片,选择“在新标签页中打开”,以便于随时查看。
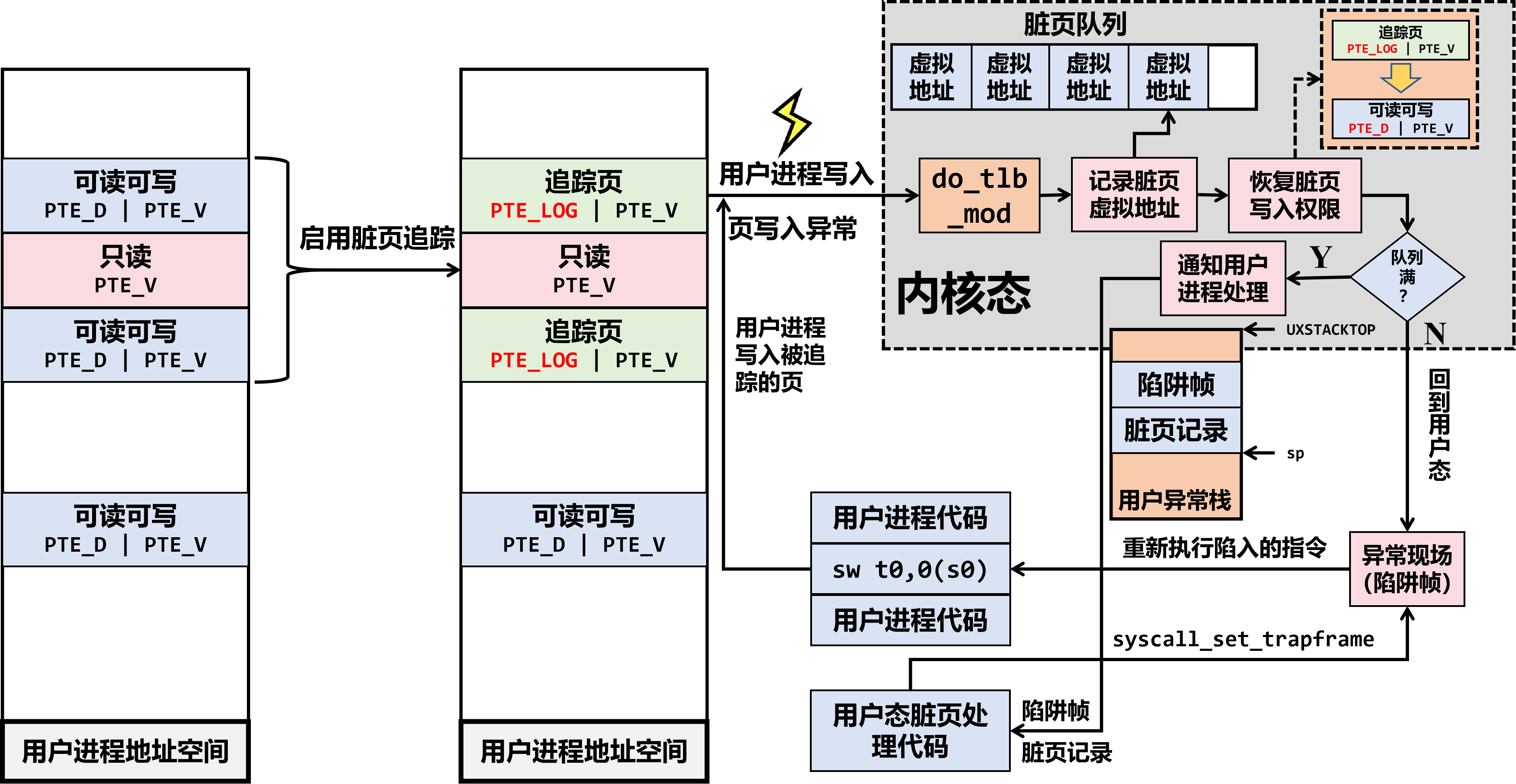
具体地:
- 用户进程首先使用“启用脏页追踪”的系统调用,指定自身地址空间内的一段地址范围启用脏页追踪,将其中的可写页面打上
PTE_LOG的追踪标志位,同时去除其PTE_D可写标志位。这样,当用户进程尝试写入被追踪的页面时,将引起页写入异常,使得内核能记录脏页;对于只读或者未映射的页面,则不进行操作; - 当用户进程写入追踪页时,将发生页写入异常,陷入内核态。内核在对应用户进程的脏页队列中记录对应页面的虚拟地址,并去掉
PTE_LOG追踪标志位,恢复该页的可写标志位。这样,当从内核态返回用户进程,重新执行写入指令时,相应的页已经是可写状态,写入指令可成功执行; - 显然,内核为每个进程维护的脏页队列大小是有限的,当脏页队列满时,类似 Lab4 课下实现的写时复制机制,内核将控制权交由用户态的处理代码,并同时将完整的脏页记录传递给该处理代码,处理代码可对脏页记录进行转储等操作,处理完毕后使用系统调用从处理逻辑回到异常现场。注意:为避免用户态处理代码访问其他追踪页时引发嵌套异常,内核需将完整的脏页记录复制到用户态的异常栈上,供用户进程访问。复制完成后,内核将清空该进程的脏页队列。
题目简介
注意:本节中的代码仅用于辅助说明,同学们无需复制,后续“题目要求”部分将给出更加详细的答题指示。
脏页记录数据结构
由于内核需要为每个用户进程记录脏页地址,在 Env 进程控制块添加字段,记录是否启用脏页记录、脏页队列、用户态脏页处理代码的地址。
1 |
|
其中,struct DirtyPageQueue 是脏页队列数据结构,同学们无需自行实现,其 API 如下,在实现本题目要求的过程中,你只应通过下方的 API 操作脏页队列,不建议自行操作 struct DirtyPageQueue 结构体,使用如下函数时,需要包含 dirtyqueue.h 头文件(#include <dirtyqueue.h>):
void dirty_init(struct DirtyPageQueue *queue):初始化脏页队列,用于在初始化进程控制块时,初始化其log_queue字段;int dirty_is_full(struct DirtyPageQueue *queue):判断对应的脏页队列是否已满,若已满,返回1,否则返回0;int dirty_is_empty(struct DirtyPageQueue *queue):判断对应的脏页队列是否为空,若为空,返回1,否则返回0;void dirty_add(struct DirtyPageQueue *queue, u_long new_dirty_page):将脏页记录new_dirty_page(新增脏页的虚拟地址,注意由于一个页面对应的是一个地址范围,此处应当传入对应页面的起始地址)加入队列。要求调用该函数时队列未满;若队列已满,将panic;u_long dirty_remove(struct DirtyPageQueue *queue):从脏页队列中获取一个脏页记录(先进先出),并将该记录出队。要求调用该函数时队列不为空;若队列为空,将panic;void dirty_clear(struct DirtyPageQueue *queue):将脏页队列清空,即,删除其中的所有脏页记录。
注意在评测时,include/dirtyqueue.h、kern/dirtyqueue.c 都将被替换为标准版本,请不要修改这些文件的内容。
页写入异常处理
在 Lab4 课下实验中,实现了 do_tlb_mod 函数,其用于处理 TLB Mod 异常。在课下实现中,对于所有的 TLB Mod 异常,都统一交由 env_user_tlb_mod_entry 处理。但在本题目中,需要根据页表项的软件标志位来区分:应当交由 env_user_tlb_mod_entry 处理 CoW 逻辑,还是交由 log_entry 处理脏页跟踪逻辑。
修改后的 do_tlb_mod 的基本框架如下(kern/tlbex.c):
1 | void do_tlb_mod(struct Trapframe *tf) { |
在课下实验中,触发 CoW 逻辑时,总是交由用户态处理。但在触发脏页记录时,并不总是交由用户态处理:
- (内核态)总是将触发脏页记录的页面的起始地址加入脏页队列中;
- (内核态)总是修改对应的页表项,去除
PTE_LOG标志位,重新设置PTE_D标志位; - 若加入后,脏页队列已满
- 若设置了用户态脏页处理逻辑
- 在用户异常栈上分配空间,分别用于存储陷阱帧和所有脏页记录,我们总是假定用户异常栈上有足够的空间来容纳陷阱帧和所有脏页记录;
- 将陷阱帧和所有脏页记录复制到用户异常栈上分配的空间中(使用
dirty_remove可逐一获取脏页记录,该函数将同时从脏页队列中移除相应记录,故所有脏页记录获取完成后,脏页队列应当已为空); - 设置返回到用户态时的状态,将
a0寄存器设置为陷阱帧的起始地址,a1寄存器设置为脏页记录的起始地址,cp0_epc寄存器设置为用户态脏页处理代码的入口地址; - 从内核态返回。
- 若未设置用户态脏页处理逻辑,则从队列中丢弃(出队)最旧的记录,保证队列是未满状态,直接从内核态返回即可。
- 若设置了用户态脏页处理逻辑
- 若加入后,脏页队列未满,直接从内核态返回即可。
注意上述过程实际维护了脏页队列的不变量:每次进入 do_tlb_mod 函数时,脏页队列都是非满的。这要求每次从 do_tlb_mod 函数返回时,保证脏页队列是非满的。
用户态脏页处理函数的结构如下:
1 | void __attribute__((noreturn)) dirty_page_full_entry(struct Trapframe *tf, u_long *dirty_pages) { |
其中参数 struct Trapframe *tf 、u_long *dirty_pages 由内核通过陷阱帧中的 a0、a1 寄存器传递。
struct Trapframe *tf包含了触发写入异常,进入内核态前的现场信息,用于在该处理函数结束时恢复现场;u_long *dirty_pages是一个一维数组,从下标 0 开始包含了从旧到新的脏页写入记录(每个记录为脏页的起始地址),数组的长度为ENV_MAX_DIRTY_LOG_COUNT(该宏在dirtyqueue.h中定义)
系统调用约定
你需要实现下列系统调用,它们的定义与功能如下:
int sys_start_dirty_log(u_long va, u_long size)
启动脏页追踪,将 [va, va + size) 范围内的所有已映射的可写页面加入脏页追踪,取消设置 PTE_D 标志,设置 PTE_LOG 标志,刷新 TLB,并返回设置了 PTE_LOG 标志的页面的数量。
要求 va、size 是 PAGE_SIZE 的整数倍,若不是,返回 -E_INVAL。
要求 [va, va + size) 范围位于合法的用户态地址范围内([UTEMP, UTOP)),否则返回 -E_INVAL。
要求当前该用户进程并未启动脏页追踪(log_enabled == 0),否则返回 -E_DIRTY_BUSY。
若成功执行,返回设置了 PTE_LOG 标志的页面的数量。
int sys_set_dirty_log_entry(u_long entry)
设置用户态脏页处理函数的入口点。无论当前是否启动了脏页都可以设置。若传入 0,表示取消设置。
若传入的参数不是 0,则要求其必须位于合法的用户态地址范围内([UTEMP, UTOP)),否则返回 -E_INVAL。
若成功执行,返回 0。
int sys_stop_dirty_log()
停止脏页追踪,停止追踪后,对应的追踪页应当能被正常写入,且不再产生脏页记录。需要遍历用户进程的地址空间([UTEMP, UTOP)),对于已映射的页面,若其有 PTE_LOG 标志,则去除该标志,重新设置 PTE_D 标志,刷新 TLB,并返回取消设置 PTE_LOG 标志的页面的数量。不修改已经设置的用户态脏页处理函数的入口点。
要求当前该用户进程已经启动脏页追踪(log_enabled == 1),否则返回 -E_DIRTY_OFF。
若成功执行,返回取消设置 PTE_LOG 标志的页面的数量。注意设置了 PTE_LOG 的页面在写入一次后,将去除对应页面的 PTE_LOG 标志,故返回的值与调用 sys_start_dirty_log 时返回的值不一定相同。
int sys_get_dirty_log(u_long *ptr)
获取本进程的一项脏页记录(先进先出),将该脏页的起始地址写入到 ptr 指针指向的内存中。已获取的脏页记录将从脏页队列中移除。
要求 ptr 指针指向的内存必须位于合法的用户态地址范围内([UTEMP, UTOP)),否则返回 -E_INVAL。
要求 ptr 指针指向的内存必须已经映射且可写,否则返回 -E_INVAL。
若目前本进程的脏页记录为空,则返回 -E_DIRTY_EMPTY,不修改 ptr 指向的内存。
若成功执行,将脏页的起始地址写入 ptr 指向的内存中,并返回 0。
注意事项
测试数据保证,如果进程启动了脏页追踪,则不会进行 fork,也不会出现 fork 后的(父、子)进程启动脏页追踪的情况。即,保证不出现一页同时有 PTE_COW 和 PTE_LOG 标记的情况。
题目要求
- 在
include/env.h的Env结构体中,添加所需的字段,注意需要导入dirtyqueue.h头文件。
1 | // 新增部分开始 |
- 在初始化
Env结构体时,初始化本题目所需的结构体字段,注意需要导入dirtyqueue.h头文件。(kern/env.c,env_alloc函数)
1 | // 新增部分开始 |
- 在
include/mmu.h中添加PTE_LOG定义。
1 | // Dirty page log. Reserved for software. |
- 在
include/syscall.h中,添加相关系统调用的枚举,请添加到 MAX_SYSNO 之前。
1 | enum { |
- 在
include/error.h中,添加所需的错误码。
1 | // 尝试在目标进程已启用脏页追踪的情况下,再次启动脏页追踪 |
- 在
kern/syscall_all.c中,在syscall_table中注册相关系统调用,下文将详细阐述系统调用的实现方式并提供部分代码,你不需要完全从头开始实现这些系统调用,注意需要导入dirtyqueue.h头文件。
1 | // 新增部分开始 |
- 在
user/include/lib.h中添加如下定义:
1 | void __attribute__((noreturn)) dirty_page_full_entry(struct Trapframe *tf, u_long *dirty_pages); |
- 在
user/lib/syscall_lib.c中添加实现,下面的代码中不含你需要实现的内容:
1 | int syscall_start_dirty_log(u_long va, u_long size) { |
- 在
kern/syscall_all.c中,实现sys_start_dirty_log系统调用:
1 | int sys_start_dirty_log(u_long va, u_long size) { |
- 在
kern/syscall_all.c中,实现sys_set_dirty_log_entry系统调用:
1 | int sys_set_dirty_log_entry(u_long entry) { |
- 在
kern/syscall_all.c中,实现sys_stop_dirty_log系统调用:
1 | int sys_stop_dirty_log() { |
- 在
kern/syscall_all.c中,实现sys_get_dirty_log系统调用:
1 | int sys_get_dirty_log(u_long *ptr) { |
- 在
kern/tlbex.c中,修改do_tlb_mod,实现脏页记录逻辑,请将课下实现的do_tlb_mod函数完全替换为下面给出的版本。注意需要导入dirtyqueue.h头文件:
1 | // 新增部分开始 |
样例输出 & 本地测试
对于如下用户程序样例:
1 |
|
应当输出:
1 | BEGIN OF TEST |
样例说明
- 在用户进程
[0x50000000, 0x5007e000]范围内映射 64 个可写页面,32 个只读页面,在该范围内启用脏页记录,记录对于可写页面的写入操作; - 测试程序对从
0x50000000开始的可写页面依次写入,内核逐个记录对脏页的写入,当脏页记录数量达到脏页队列容量 32 时,调用用户态脏页处理函数。脏页处理函数依次打印 32 个脏页记录 (从0x50000000到0x5003e000,共 32 个记录,输出中以[dirty_page_full_entry]开头); - 共对 43 个可写页面进行写入,当写入 32 个可写页面时,触发用户态脏页处理,剩余的 11 次写入继续记录在脏页队列中,通过
syscall_get_dirty_log依次获取,打印出从0x50040000到0x50054000的 11 个记录(从输出中Remaining entries:开始的 11 行); - 注意程序中实际写入了地址
0x50002004、0x50004008,但脏页记录应当对齐页面边界,记录为0x50002000、0x50004000(输出中[dirty_page_full_entry] [01]、[dirty_page_full_entry] [02]条目)。
你可以使用
make test lab=4_dirty_page_sample && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=4_dirty_page_sample && make run在本地测试上述样例(开启优化)
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测。
$ cd ~/学号 $ git add -A $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
在线评测时,所有的 .mk 文件、所有的 Makefile 文件、init/init.c、include/dirtyqueue.h、kern/dirtyqueue.c以及 tests/ 和 tools/ 目录下的所有文件都可能被替换为标准版本,因此请同学们在本地开发时,不要在这些文件中编写实际功能所依赖的代码。
测试点和分数说明如下:
| 测试点序号 | 评测内容 | 分数 |
|---|---|---|
| 1 | 样例 | 3 |
| 2 | sys_start_dirty_log 的前置条件(地址合法性、是否启动脏页记录) |
5 |
| 3 | sys_start_dirty_log 对页表的修改、返回值 |
5 |
| 4 | sys_start_dirty_log 维护 TLB |
5 |
| 5 | sys_stop_dirty_log 的前置条件(是否启动脏页记录) |
5 |
| 6 | sys_stop_dirty_log 对页表的修改、返回值 |
5 |
| 7 | sys_stop_dirty_log 维护 TLB |
5 |
| 8 | sys_set_dirty_log_entry 设置用户脏页处理函数 |
10 |
| 9 | sys_get_dirty_log 的前置条件(地址合法性、队列是否为空) |
5 |
| 10 | sys_get_dirty_log 应以先进先出的方式返回脏页记录 |
5 |
| 11 | do_tlb_mod 处理页写入异常(脏页队列未满) |
5 |
| 12 | do_tlb_mod 处理页写入异常(脏页队列已满) |
5 |
| 13 | 用户态调用有关系统调用(弱测) | 10 |
| 14 | 用户态测试脏页记录(syscall_get_dirty_log) |
10 |
| 15 | 综合测试 | 17 |
提示:本题测试点独立性相对较高,且不依赖样例。若未完全实现,也可以提交以获得部分分数。
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5case:6case:7case:8case:9case:10case:11case:12case:13case:14case:15
Lab 5 Exam
准备工作:创建并切换到 lab5-exam-off 分支
请基于已完成的 lab5 提交自动初始化 lab5-exam-off 分支,然后在开发机依次执行:
$ cd ~/学号 $ git fetch $ git checkout lab5-exam-off
初始化的 lab5-exam-off 分支基于课下完成的 lab5 分支,并且在 tests 目录下添加了 lab5-ls 样例测试目录。
题目背景 & 题目描述
在 Linux 中, ls(单词 list 的简写)是一条常用命令,可以显示指定工作目录下的内容(列出目前工作目录所含的文件及子目录)。附带参数的 ls -a 可以显示出包含隐藏文件在内的所有内容。
在本次测试中,我们希望你实现一个简易的目录列出服务函数 int file_list(const char *path, u_int all, struct Ls_res *res) 。该函数支持列出无通配符绝对路径 path 对应的目录下的所有文件的名字(当参数 all 非 0 时额外列出以 . 开头的隐藏文件,不用考虑也不用输出 ./ 和 ../,无需递归列出子目录中的文件),并记录文件数量(当 all 非 0 时计入隐藏文件数量),将结果存入 res 指向的预定义结构体。额外地,你需要区分非目录文件和目录文件:对于目录文件,你需要在目录文件原有名字的后面增加一个 / 字符来区分。
预定义的存放结果的结构体如下(后面“实现思路”部分还会再次给出):
1 | struct Ls_res { |
为了确保你的理解正确,这里给出一个例子。对于以下的目录结构,
1 | / |
使用 file_list(path="/", all=0, res) 后,res 中的内容如下:
1 | // file_name 中的顺序不影响评测 |
而使用 file_list(path="/", all=1, res) 后,res 中的内容如下:
1 | // file_name 中的顺序不影响评测 |
更为具体的行为规则与实现提示如下。
- 关于
all参数:- 当
all != 0时,列出所有非空目录项(包括以.开头的隐藏文件); - 当
all == 0时,不列出以.开头的文件名。
- 当
- 关于普通文件与目录文件的区分:
- 如果为目录文件,在
res记录该文件名字时末尾添加/以示区分(例如dir/); - 如果为普通文件,只记录名字(例如
file)。
- 如果为目录文件,在
- 在识别文件名时,你需要跳过空名文件(文件名以
\0开头的文件,这表示它们是磁盘块中还未被使用的文件控制块或被删除了的文件对应的文件控制块)以保证计数正确。 - 测试点保证你无需考虑找到的指定目录下文件名过长的问题。
Ls_res结构体成员file_name应当从file_name[0]开始填充(无需考虑目录下的文件名顺序问题),成员count用于记录本次请求得到的文件数量,否则不保证评测正确。- 函数返回值(错误码与课程约定保持一致):
- 路径不存在或找不到:
-E_NOT_FOUND - 路径非法(空或过长):
-E_BAD_PATH - 正常执行:返回
0
- 路径不存在或找不到:
- 测试点保证:测试点保证当
path能找到时一定是目录,且path以/结尾;path以无通配符的绝对路径给出。
实现思路
- 在
user/include/lib.h的#define pages ((const volatile struct Page *)UPAGES)定义后添加查询结果结构体:
1 |
|
- 在
user/include/lib.h的// file.c部分添加声明:
int file_list(const char *path, u_int all, struct Ls_res *res);
- 将
file_list函数的实现添加到user/lib/file.c:
1 | int file_list(const char *path, u_int all, struct Ls_res *res) { |
- 在
user/include/fsreq.h中的枚举类型中增加一个对于文件系统的请求类型FSREQ_LS,请注意要把它放在MAX_FSREQNO前; - 在
user/include/fsreq.h的#endif之前添加请求结构体:
1 | struct Fsreq_ls { |
- 在
user/include/lib.h的// fsipc.c部分新增声明:
int fsipc_ls(const char *path, u_int all, struct Ls_res *res);
- 在
user/lib/fsipc.c中添加fsipc_ls函数的实现:
1 | int fsipc_ls(const char *path, u_int all, struct Ls_res *res) { |
- 在
fs/serv.c的服务函数分发表serve_table最后新增一项:
[FSREQ_LS] = serve_ls
- 在
fs/serv.c中添加serve_ls函数的实现:
1 | void serve_ls(u_int envid, struct Fsreq_ls *rq) { |
- 在
fs/serv.h中添加声明:
int list_files(const char *path, u_int all, struct Ls_res *res);
- 在
fs/fs.c中完成list_files函数,实现本服务的核心功能。
实现提示
可以在 fs/fs.c 中构建一个辅助函数 list_dir_entries 用于实现核心功能(遍历目录下的所有文件,将信息填入 res ):
1 | int list_dir_entries(struct File *ls_dir, u_int all, struct Ls_res *res) { |
然后调用辅助函数实现目标函数功能:
1 | int list_files(const char *path, u_int all, struct Ls_res *res) { |
样例输出 & 本地测试
对于测试样例文件
1 |
|
和测试样例文件结构
1 | / |
应当看到以下输出:
1 | check_1: 'count' correct! |
你可以使用 make test lab=5_ls && make run 在本地测试上述样例。
如果需要自行设置样例或更改样例评测输出,可以修改 tests/lab5_ls/ 中 rootfs/ 中的文件结构、ls_check.c 中的评测标准与评测输出。
提交评测 & 评测标准
请在开发机中执行下列命令后,在课程网站上提交评测:
$ cd ~/学号/ $ git add -A $ git commit -m "message" # 请将 message 改为有意义的信息 $ git push
测试点说明及分数分布如下:
| 测试点序号 | 评测说明 | 分值 |
|---|---|---|
| 1 | 样例 | 5 |
| 2 | 仅包含非隐藏目录 | 15 |
| 3 | 仅包含非隐藏目录和非隐藏文件 | 15 |
| 4 | 仅包含非隐藏文件和隐藏文件 | 15 |
| 5 | 综合测试 | 50 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1 样例case:2 仅包含非隐藏目录case:3 仅包含非隐藏目录和非隐藏文件case:4 仅包含非隐藏文件和隐藏文件case:5 综合测试
Lab 5 Extra
准备工作
请在自动初始化分支后,在开发机依次执行:
$ cd ~/学号 $ git fetch $ git checkout lab5-extra-off
初始化的 lab5-extra-off 分支基于你课下完成的 lab5 分支,并且在 tests 目录下添加了 lab5_verity 样例测试目录。
题目背景 & 功能概览
完成 Lab5 后,MOS 已经能够通过文件系统服务进程管理普通文件的打开、映射、读写、截断和写回。本题在此基础上加入一个简化的 Verity(完整性校验)机制:当一个普通文件被 seal(密封)后,文件系统需要把它视为只读文件,并在之后的访问过程中校验其内容是否仍与 seal 时一致。
本题需要支持以下功能:
- 对普通文件调用
fseal(path),记录该普通文件当前的大小和全文件摘要,并把它标记为 sealed(被密封)。 - 对 sealed 普通文件调用
fverify(path),重新计算摘要并与保存值比较,不一致返回-E_VERIFY。 - sealed 文件不能再通过正常写路径修改。使用
O_WRONLY、O_RDWR或带O_TRUNC打开 sealed 文件时,应返回-E_SEALED。 - 使用
O_RDONLY打开 sealed 文件时,应先进行完整性校验。
本题还提供了 fs_debug_corrupt() 作为测试辅助接口。它用于绕过正常写路径篡改数据块,帮助检查校验逻辑是否能发现内容变化。
本题新增的错误码含义如下:
-E_VERIFY:sealed 文件摘要校验失败。-E_SEALED:试图通过正常写路径修改 sealed 文件。
实现思路
1. Verity 核心实现
在 include/error.h 中引入本题所需错误码:
1 | // File not a valid executable |
在 user/include/fs.h 中引入本题所需数据结构:
1 | struct File { |
注意:
FileVerity存放在struct File末尾的f_pad中,不改变FILE_STRUCT_SIZE。v_magic当值为FVERITY_MAGIC时,说明f_pad中保存的是有效的 verity 数据。- 当
v_flags包含FVERITY_SEALED时表示文件已 seal。 v_size记录 seal 时的文件大小,用于在校验时发现文件大小变化。v_digest记录 seal 时的全文件摘要,用于之后的完整性校验。- 你可以调用
file_verity()函数来得到该文件的 FileVerity 结构体。 - 你可以调用
file_is_sealed()函数来判断一个文件是否 sealed 。
在 fs/verity_core.c 中补全 Verity 机制核心实现:
在
file_seal()中为普通文件建立 verity 数据。1
2
3
4
5
6
7
8
9
10
11
12if (!file_regular(f)) {
return -E_INVAL;
}
// Lab5-Extra: Your code here. (1/6)
// 调用 file_digest() 计算当前文件的全文件摘要。
// 然后填写该文件的 FileVerity 结构体,
// 需要填写的字段有:v_magic、v_flags、v_size 和 v_digest。
// Lab5-Extra: End (1/6).
file_close(f);
``
注意:
int file_digest(struct File *f, uint32_t *hash_store)用于计算文件f当前内容的全文件摘要。调用成功时返回0,并把摘要写入第二个参数指向的变量;调用失败时返回对应错误码。你可以直接调用该函数来计算当前文件的全文件摘要。- 可调用
file_verity(f)得到该文件的FileVerity结构体; v_size应填写为当前文件大小f_size;- 若
file_digest()返回错误,应直接返回该错误码。
在
file_verify()中校验 sealed 文件内容是否仍与 seal 时一致。1
2
3
4
5
6
7
8
9
10if (f->f_size != v->v_size) {
return -E_VERIFY;
}
// Lab5-Extra: Your code here. (2/6)
// 调用 file_digest() 重新计算摘要,并与 v->v_digest 比较。
// Lab5-Extra: End (2/6).
return 0;
注意:
- 若重新计算摘要失败,应直接返回该错误码;
- 若重新计算出的摘要与
v->v_digest不一致,返回-E_VERIFY; - 校验通过时返回
0。
2. 用户态接口与文件系统请求
本题需要把三个新用户态请求接入文件系统服务端。整体链路如下:
1 | fseal(path) -> fsipc_seal(path) -> FSREQ_SEAL -> serve_seal() -> file_seal() |
下面以 fs_debug_corrupt(...) -> fsipc_debug_corrupt(...) -> FSREQ_DEBUG_CORRUPT -> serve_debug_corrupt() -> file_debug_corrupt() 这条链路为示例进行接入,另外两条 seal / verify 链路请在后文参照它自行完成。
2.1 注册请求号
在 user/include/fsreq.h 中引入 FSREQ_DEBUG_CORRUPT 请求号:
1 | FSREQ_REMOVE, |
注意新引入的请求号要在 MAX_FSREQNO 之前。
2.2 定义请求结构体
然后加入所需的请求结构体:
1 | MAX_FSREQNO, |
2.3 声明用户态函数
在 user/include/lib.h 中加入所需函数声明:
先引入新增的 fsipc 函数声明:
1 | int fsipc_sync(void); |
再引入所需的用户接口函数声明:
1 | int ftruncate(int fd, u_int size); |
2.4 实现用户态 fsipc 函数
在 user/lib/fsipc.c 中实现函数 fsipc_debug_corrupt():
1 | int fsipc_sync(void) { |
2.5 实现用户接口
在 user/lib/file.c 中实现函数 fs_debug_corrupt()。该函数作为用户程序直接调用的接口只负责转发参数:
修改后应为:
1 | int sync(void) { |
2.6 注册服务端处理函数
fs/verity_serv.c 已经给出了三条链路的服务端处理函数。只需要在 fs/serv.c 的 serve_table 中注册好对应的函数即可:
1 | void *serve_table[MAX_FSREQNO] = { |
2.7 参照示例完成 seal / verify 链路
请你添加好示例链路后,再参照示例,将 fseal(path) 和 fverify(path) 两条链路也接入 IPC,这两条链路只需要传递 path 参数,所以共用 struct Fsreq_path 请求结构体。
接入这两条链路时用到的信息如下:
1 | // 请求号 |
此处给出一个 TODO list 方便同学们对照:
- 注册请求号
- 新增请求结构体
- 声明用户态函数,包括
fsipc与接口函数 - 实现
fsipc接口函数 - 自行实现用户态接口函数
- 在
serve_table中注册好对应的serve函数 (serve_seal与serve_verify)
3. 在 serve_open() 中加入 sealed 文件的打开检查
先在fs/serv.c文件顶部引入 fs/verity_internal.h:
1 |
|
然后在 serve_open() 中加入 sealed 文件的打开检查,位置在保存文件指针之后、执行 O_TRUNC 之前:
1 | // Save the file pointer. |
注意:
你可以调用
file_is_sealed()函数来判断一个文件是否 sealed 。你可以使用
(rq->req_omode & O_ACCMODE)判断文件打开模式。如果你对文件打开模式不熟悉,可以查阅user\include\lib.h。
样例输出 & 本地测试
对于如下用户程序样例:
1 |
|
应当输出以下关键内容:
1 | verity 1 begin |
样例说明
- 样例创建空文件
/v1_empty,调用fseal()生成摘要信息,再调用fverify()校验,随后以只读方式打开、读取并关闭该 sealed 文件。 - 样例创建短文件
/v1_short,写入hello verity,检查短文件的 seal/verify、重复 seal、只读打开、读取内容和关闭流程。 - 该样例同时也是提交评测中的第 1 个测试点,
make test lab=5_verity会运行与该测试点一致的本地样例。
你可以使用:
make test lab=5_verity && make run在本地测试上述样例(调试模式)MOS_PROFILE=release make test lab=5_verity && make run在本地测试上述样例(开启优化)
提交评测
$ cd ~/学号 $ git add -A $ git commit -m "message" $ git push
在线评测时,.mk 文件、Makefile 文件、init/init.c、tests/ 和 tools/ 目录可能被替换为标准版本,请不要把实际功能逻辑写在这些文件中。
评测标准
| 测试点序号 | 评测内容 | 分数 |
|---|---|---|
| 1 | 样例:空文件和短文件 seal/verify | 15 |
| 2 | 接入新增IPC请求链路 | 20 |
| 3 | Verity 核心实现 | 20 |
| 4 | sealed 文件写保护和 open 校验 | 25 |
| 5 | 综合测试 | 20 |
测试点依赖关系如下(箭头方向表示依赖方向):
case:1case:2case:3case:4case:5
lab6
可能更新
- Title: OS2026上机真题
- Author: Connor
- Created at : 2026-06-02 23:35:20
- Updated at : 2026-06-03 11:02:43
- Link: https://redefine.ohevan.com/2026/06/02/OS2026Question/
- License: This work is licensed under CC BY-NC-SA 4.0.